

Migrating Critical Traffic At Scale with No Downtime?—?Part 1
The Netflix TechBlog
MAY 4, 2023
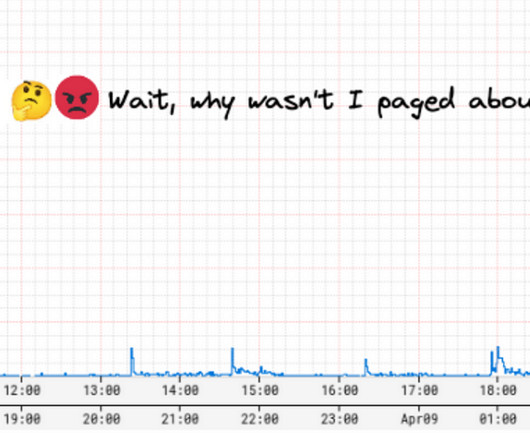
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. It provides a good read on the availability and latency ranges under different production conditions.











































Let's personalize your content