

Building Resiliency With Effective Error Management
DZone
JANUARY 23, 2022
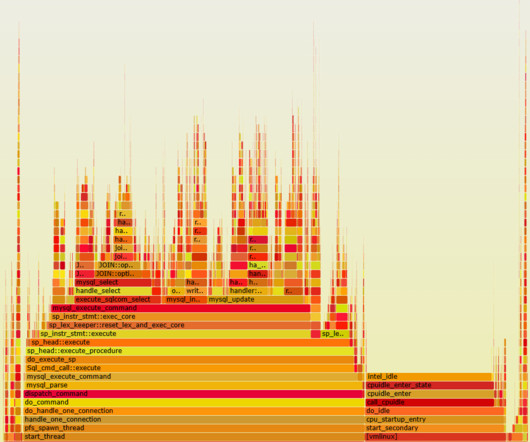
Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. Redundancy in power, network, cooling systems, and possibly everything else relevant. Monitor the servers on various parameters and build redundancy.





































Let's personalize your content