Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
 Design Development Efficiency Latency
Design Development Efficiency Latency 
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.

DZone
JUNE 22, 2023
The goal is to help developers, technical managers, and business owners understand the importance of API performance optimization and how they can improve the speed, scalability, and reliability of their APIs. What Is API Performance Optimization?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
The Netflix TechBlog
SEPTEMBER 29, 2022
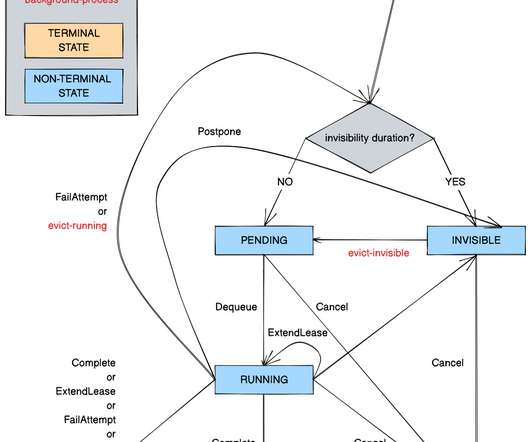
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5

Scalegrid
MARCH 28, 2024
Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load. Despite its advantages, Redis’s versatility can introduce complexities, potentially challenging developers familiar with simpler solutions such as Memcached.

Dynatrace
JANUARY 31, 2024
Development and demand for AI tools come with a growing concern about their environmental cost. Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources.

Dynatrace
SEPTEMBER 13, 2023
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.

The Netflix TechBlog
MARCH 7, 2024
Since its inception , Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. Rapid development is enabled via Metaflow namespaces , so individual developers can develop without interfering with production deployments.

Expert insights. Personalized for you.








































Let's personalize your content