

Is DevOps dead? Exploring the changing IT landscape and future of DevOps
Dynatrace
JUNE 6, 2023
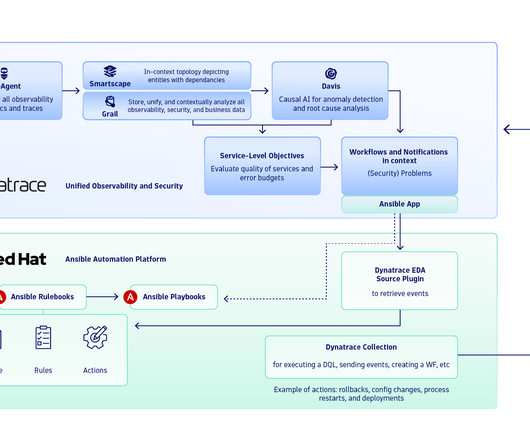
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.










































Let's personalize your content