

Dynatrace Managed turnkey Premium High Availability for globally distributed data centers (Early Adopter)
Dynatrace
JUNE 25, 2020
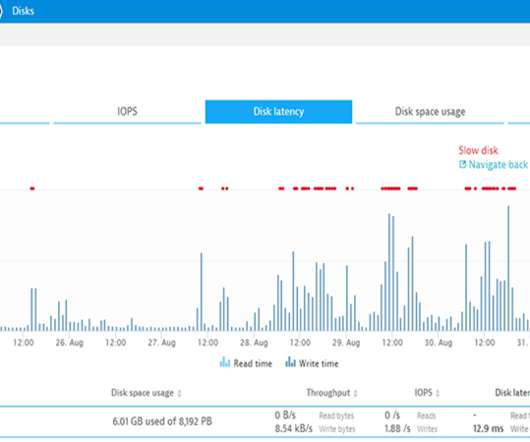
The network latency between cluster nodes should be around 10 ms or less. With Dynatrace actively managing business-critical applications, some of our globally distributed enterprise customers require Dynatrace Managed to continue operating even when an entire data center goes down. Minimized cross-data center network traffic.










































Let's personalize your content