

Supporting Diverse ML Systems at Netflix
The Netflix TechBlog
MARCH 7, 2024
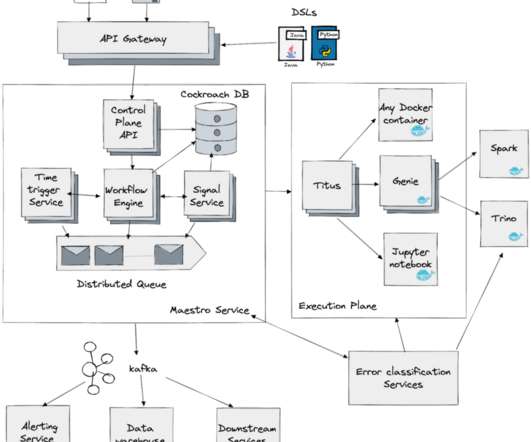
For ETL and other heavy lifting of data, we mainly rely on Apache Spark. In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. We use Apache Arrow to decode Parquet and to host an in-memory representation of data.























Let's personalize your content