

Apache Doris for Log and Time Series Data Analysis
DZone
MAY 25, 2024
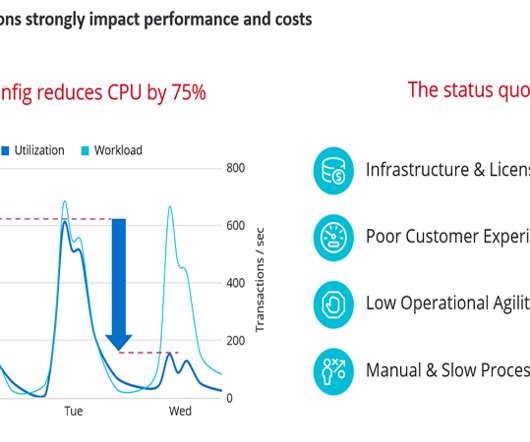
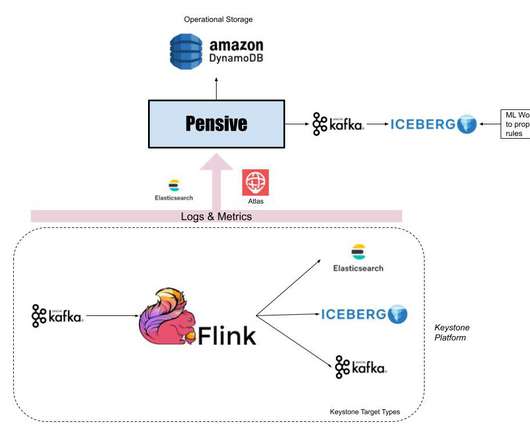
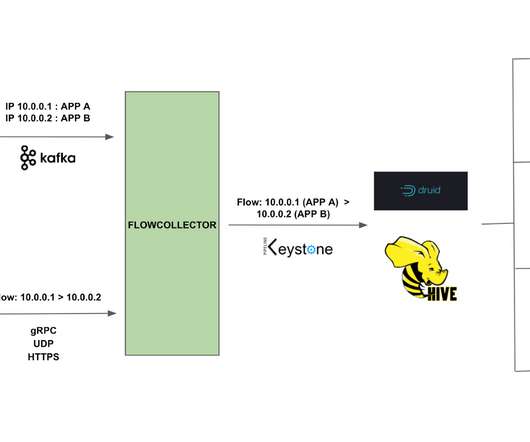
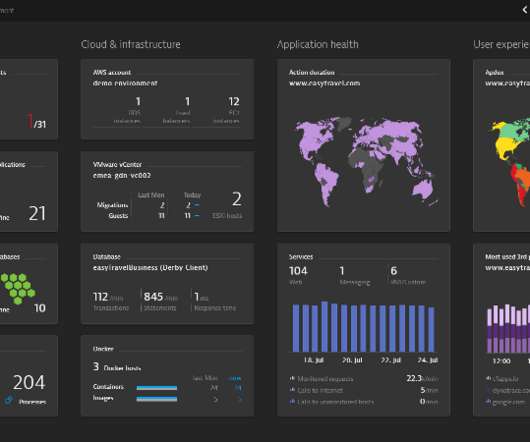
As NetEase expands its business horizons, the logs and time series data it receives explode, and problems like surging storage costs and declining stability come. As NetEase's pick among all big data components for platform upgrades, Apache Doris fits into both scenarios and brings much faster query performance.







































Let's personalize your content