

Driving your FinOps strategy with observability best practices
Dynatrace
MARCH 18, 2024
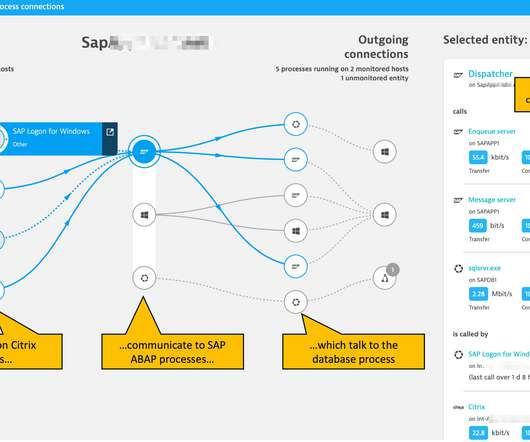
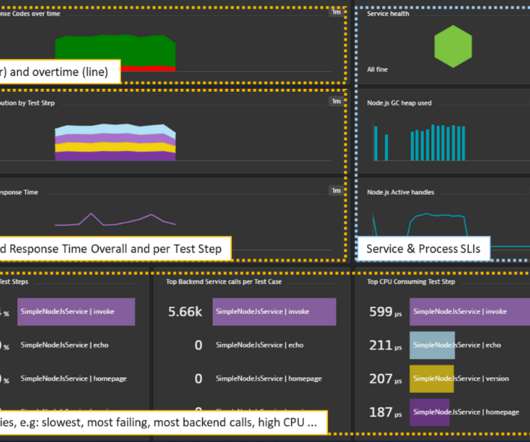
Are there rogue servers running in the environment where ITOps, CloudOps, or another team can’t assign or identify who’s financially responsible for it? An organization can ask Dynatrace, “Have you seen any oversized servers over X amount of time?” ” But Dynatrace goes further.









































Let's personalize your content