

Real user monitoring vs. synthetic monitoring: Understanding best practices
Dynatrace
JUNE 27, 2022
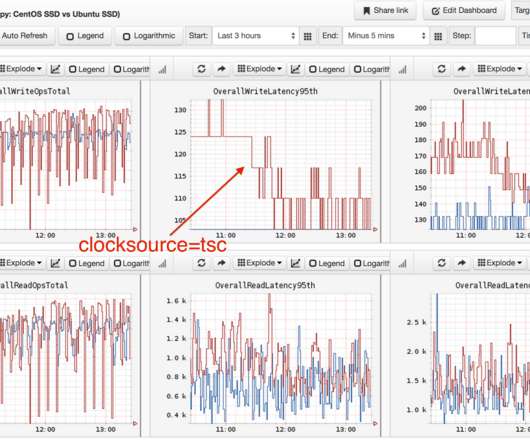
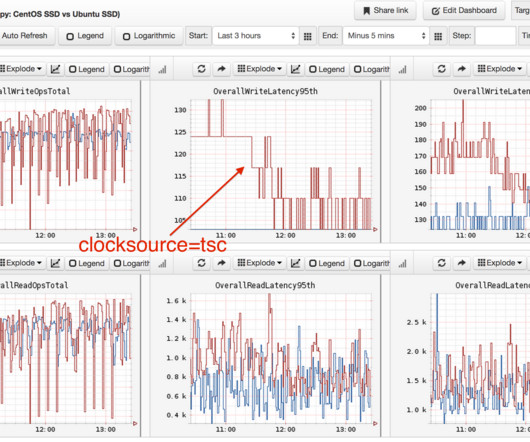
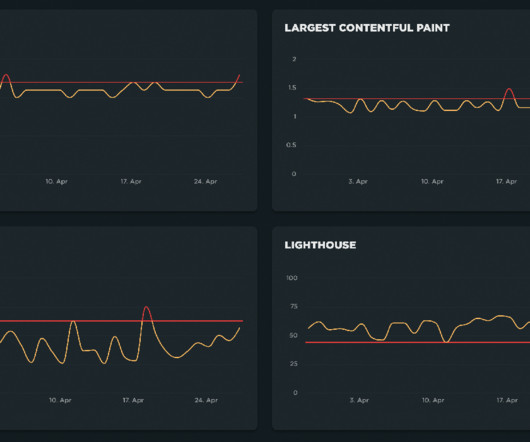
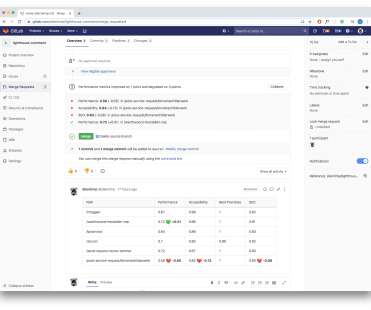
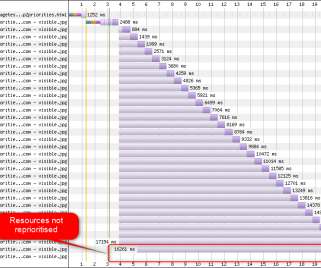
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. Because pre-production environments are used for testing before an application is released to end users, teams have no access to real-user data. What is synthetic monitoring?




































Let's personalize your content