

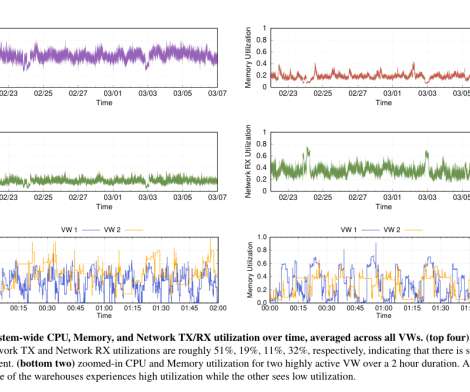
Medallion Architecture: Efficient Batch and Stream Processing Data Pipelines With Azure Databricks and Delta Lake
DZone
JULY 13, 2023
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. This article explores the concepts of Medallion Architecture and demonstrates how to implement batch and stream processing pipelines using Azure Databricks and Delta Lake.











































Let's personalize your content