
How Netflix uses eBPF flow logs at scale for network insight
The Netflix TechBlog
JUNE 7, 2021
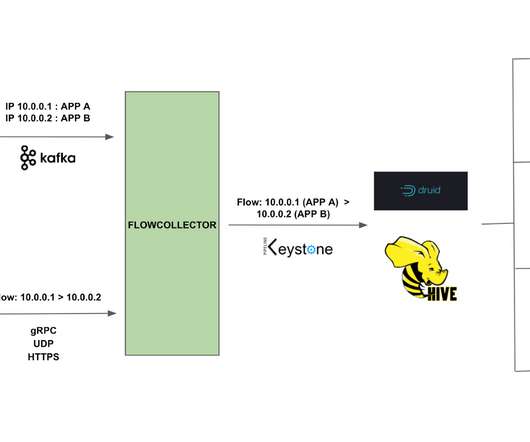
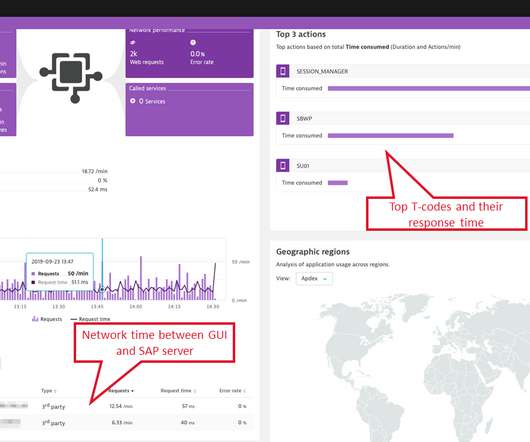
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.












































Let's personalize your content