

Five-nines availability: Always-on infrastructure delivers system availability during the holidays’ peak loads
Dynatrace
NOVEMBER 22, 2022
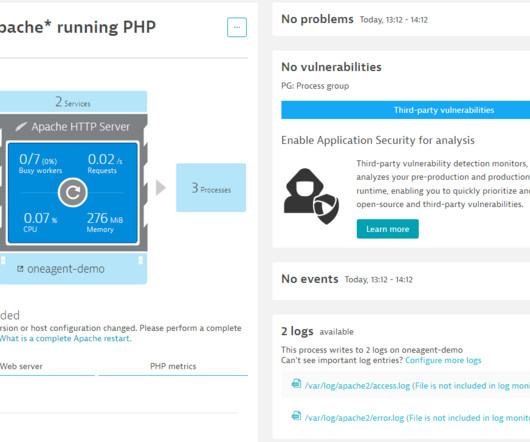
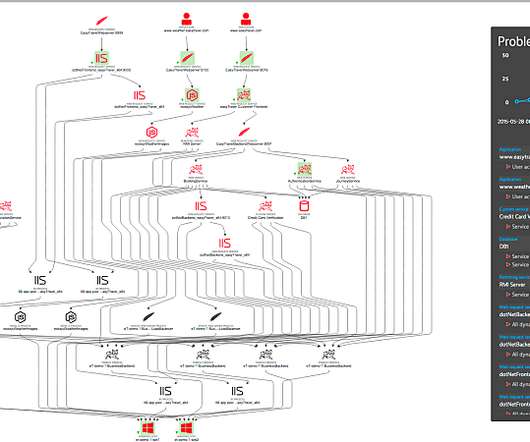
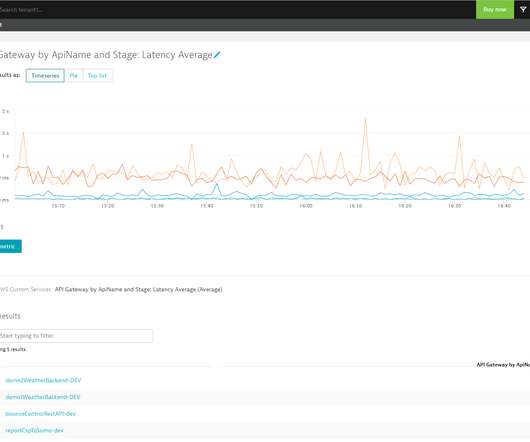
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).








































Let's personalize your content