

Comparing Approaches to Durability in Low Latency Messaging Queues
DZone
AUGUST 2, 2022
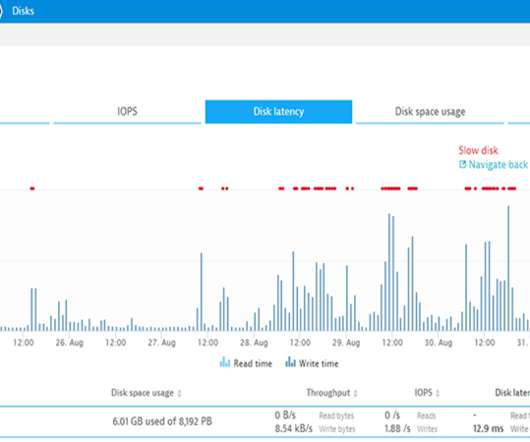
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. Little’s Law and Why Latency Matters. In many cases, the assumption is that as long as throughput is high enough, the latency won’t be a problem.











































Let's personalize your content