

Dynatrace OpenPipeline: Stream processing data ingestion converges observability, security, and business data at massive scale for analytics and automation in context
Dynatrace
JANUARY 31, 2024
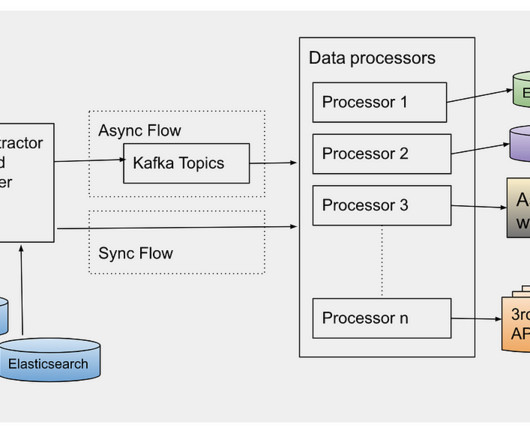
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Understanding the context.











































Let's personalize your content