

Implementing AWS well-architected pillars with automated workflows
Dynatrace
SEPTEMBER 13, 2023
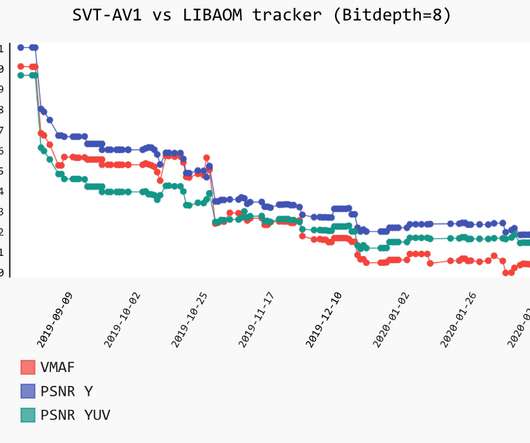
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.








































Let's personalize your content