

Crucial Redis Monitoring Metrics You Must Watch
Scalegrid
JANUARY 25, 2024
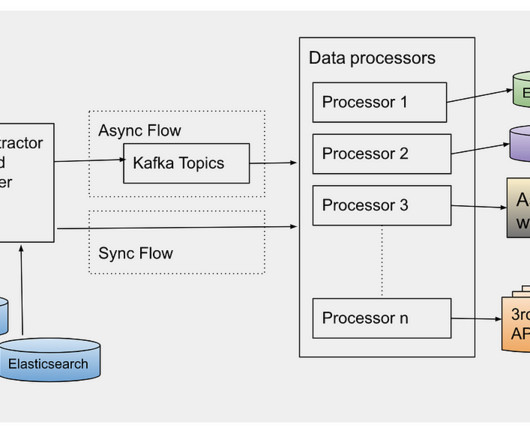
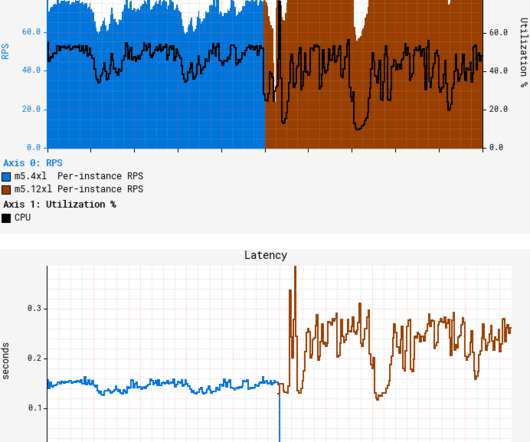
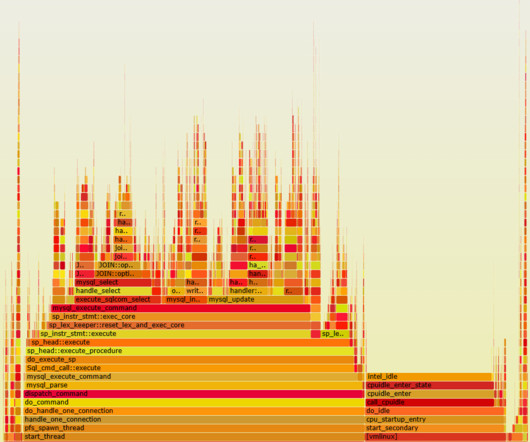
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.






































Let's personalize your content