

Migrating Critical Traffic At Scale with No Downtime?—?Part 1
The Netflix TechBlog
MAY 4, 2023
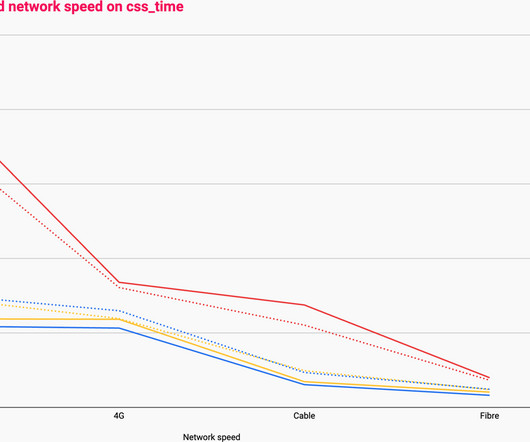
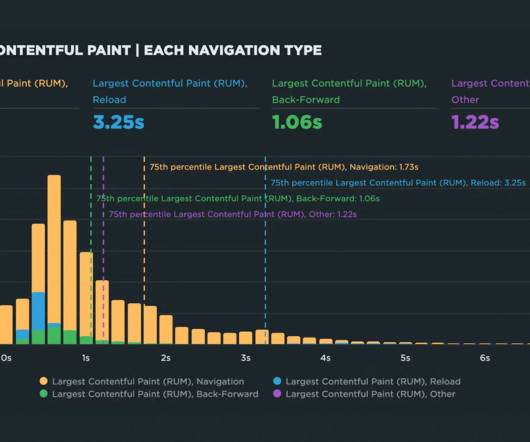
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. The batch job creates a high-level summary that captures some key comparison metrics.

























Let's personalize your content