

What is Greenplum Database? Intro to the Big Data Database
Scalegrid
MAY 13, 2020
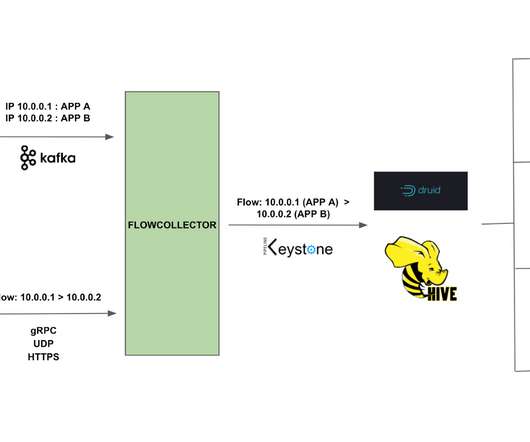
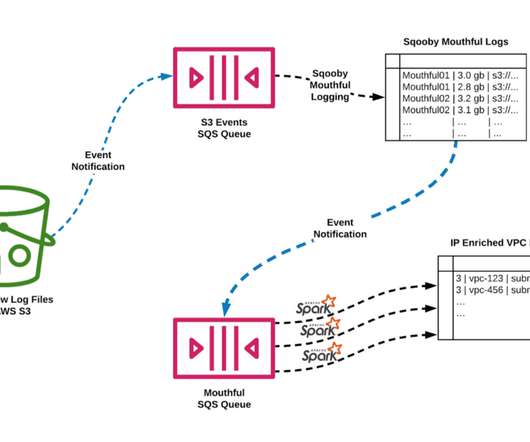
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages.









































Let's personalize your content