
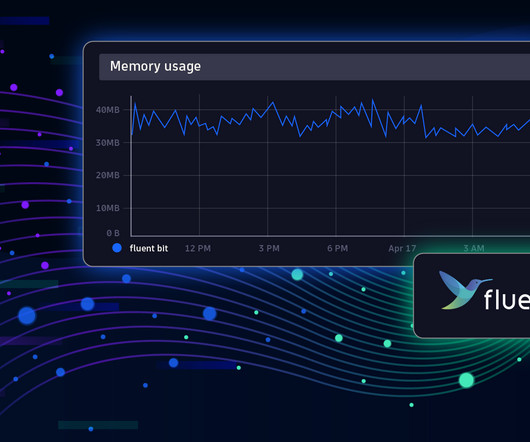
Best practices for Fluent Bit 3.0
Dynatrace
MAY 7, 2024
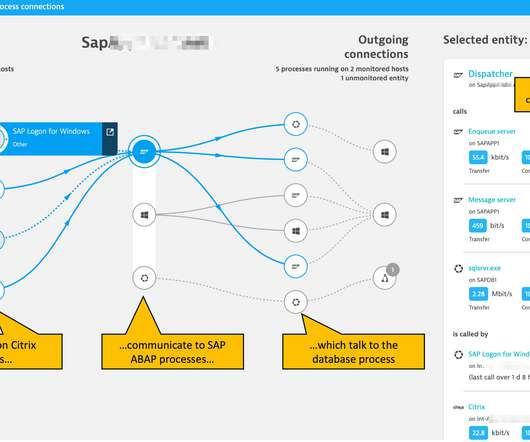
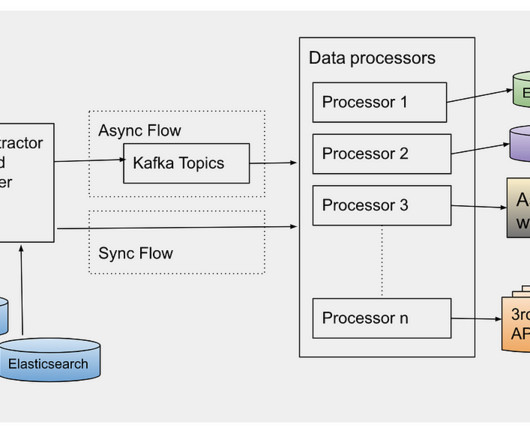
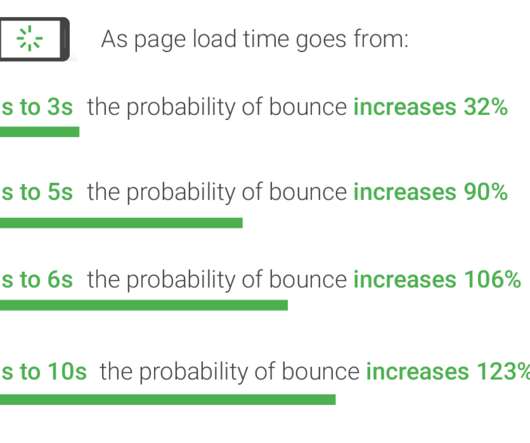
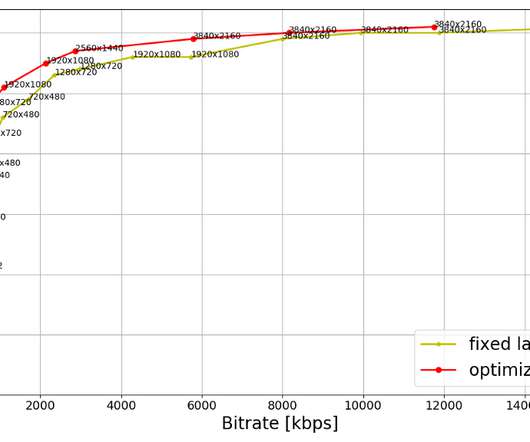
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Observability: Elevating Logs, Metrics, and Traces! What is Fluent Bit?







































Let's personalize your content