
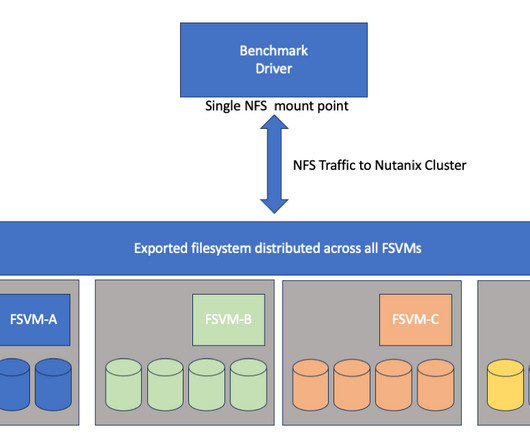
Running the ML-Perf Storage benchmark on Nutanix files.
n0derunner
SEPTEMBER 15, 2023
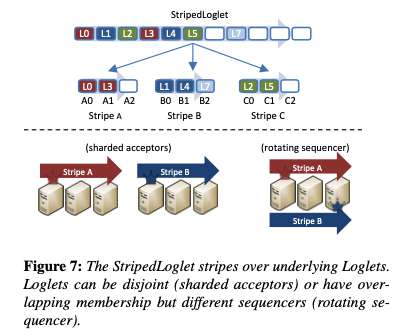
Some technical notes on our submission to the benchmark committee. Background For the past few months engineers from Nutanix have been participating in the MLPerftm Storage benchmark which is designed to measure the storage performance required for ML training workloads. appeared first on n0derunner.









































Let's personalize your content