
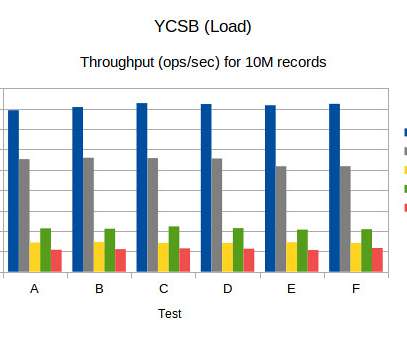
Benchmark (YCSB) numbers for Redis, MongoDB, Couchbase2, Yugabyte and BangDB
High Scalability
FEBRUARY 17, 2021
Application example: user profile cache, where profiles are constructed elsewhere (e.g., The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Workload C: Read only. This workload is 100% read. Conclusion.







































Let's personalize your content