

Comparing Approaches to Durability in Low Latency Messaging Queues
DZone
AUGUST 2, 2022
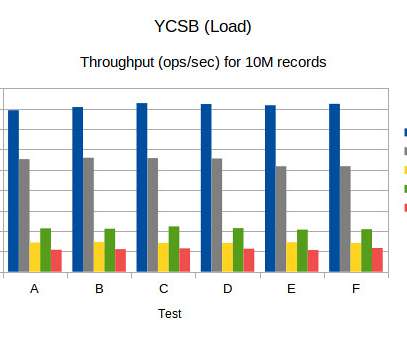
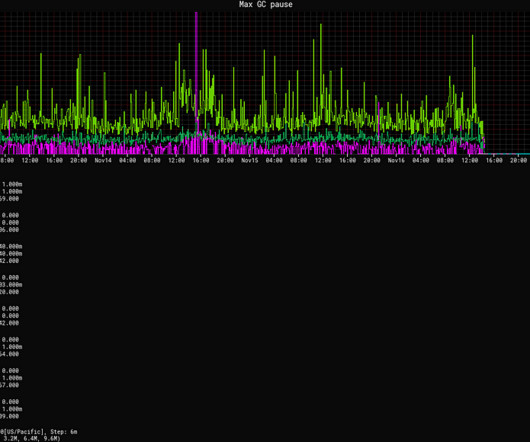
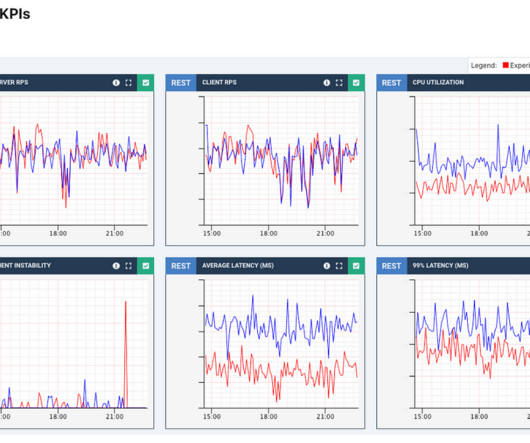
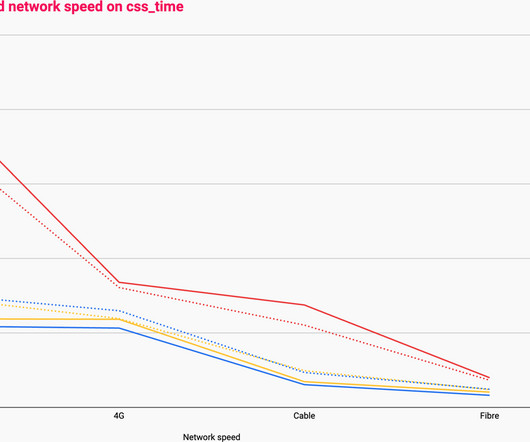
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example. This is the first time I have benchmarked it with a realistic example.





































Let's personalize your content