

Efficient SLO event integration powers successful AIOps
Dynatrace
APRIL 5, 2024
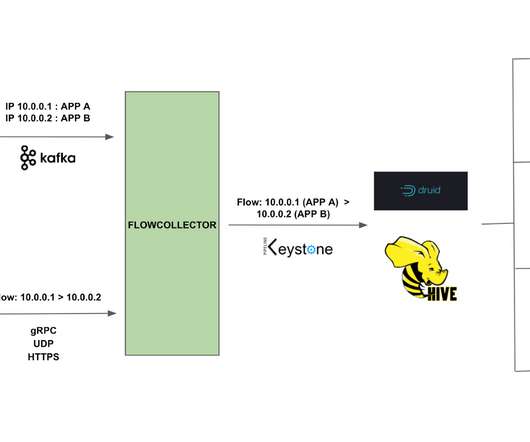
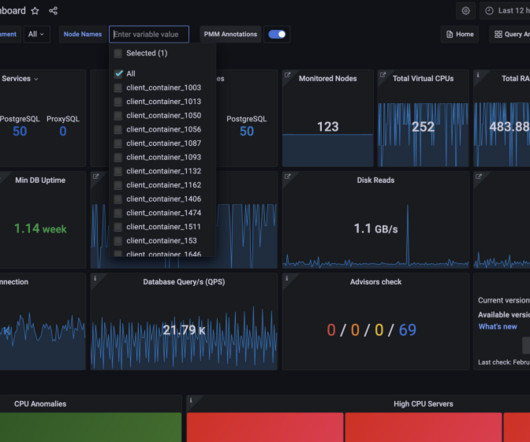
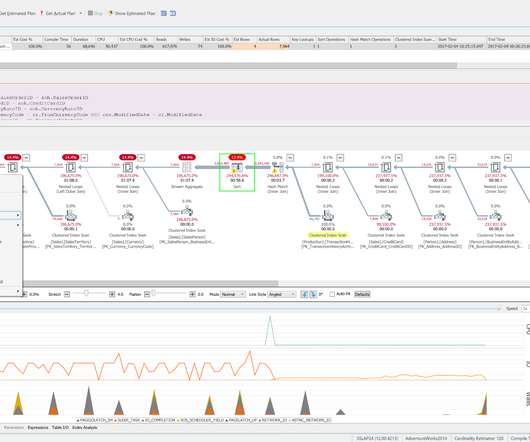
For instance, consider how fine-tuned failure rate detection can provide insights for comprehensive understanding. Please refer to How to fine-tune failure detection (dynatrace.com) for further information. Let’s assume we created a service-availability SLO, monitoring the request failure count against the overall request counts.











































Let's personalize your content