

What is Greenplum Database? Intro to the Big Data Database
Scalegrid
MAY 13, 2020
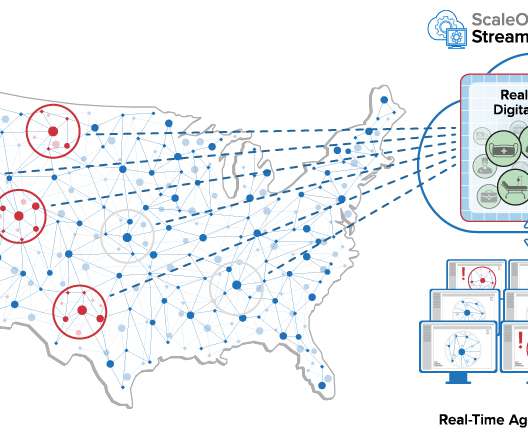
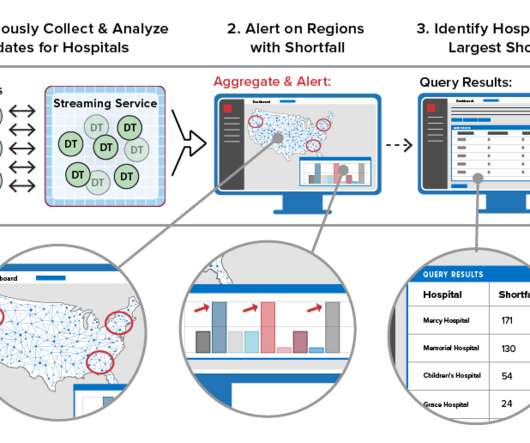
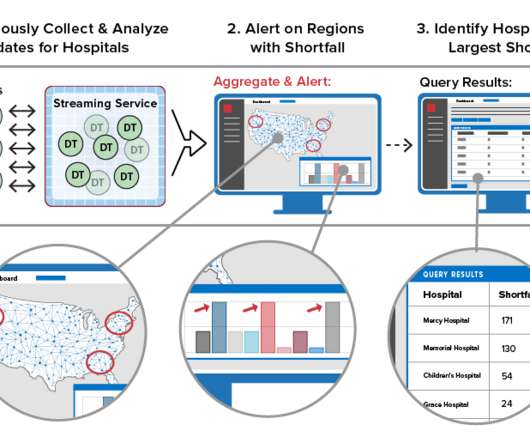
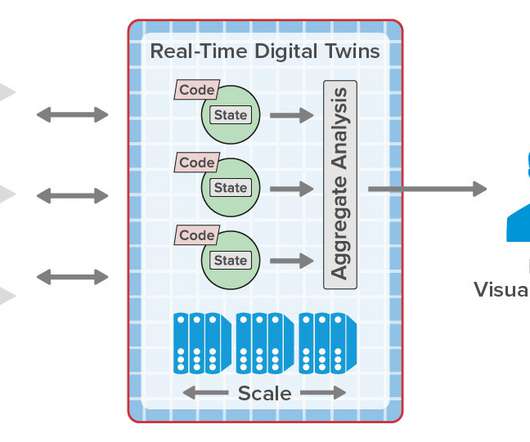
When handling large amounts of complex data, or big data, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum features a cost-based query optimizer for large-scale, big data workloads. Query Optimization.





































Let's personalize your content