
Detecting Speech and Music in Audio Content
The Netflix TechBlog
NOVEMBER 13, 2023
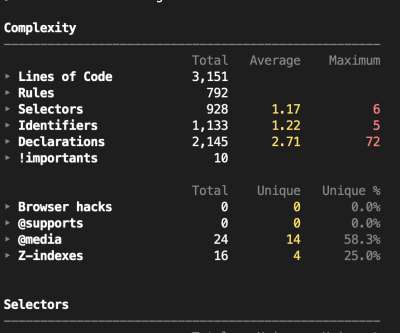
Content, genre and languages Instead of augmenting or synthesizing training data, we sample the large scale data available in the Netflix catalog with noisy labels. Training examples were produced between 2016 and 2019, in 13 countries, with 60% of the titles originating in the USA. We address the challenge from a different angle.
























Let's personalize your content