

Low Overhead Continuous Contextual Production Profiling
DZone
JUNE 15, 2023
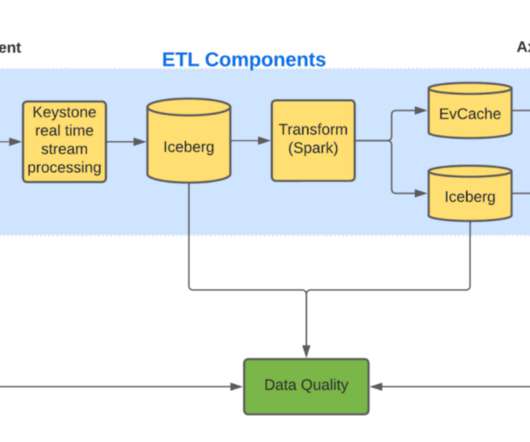
In order to gain insight into these problems, we gather a range of metrics and logs to monitor the utilization of system resources such as CPU, memory, and application-specific latencies. It is worth noting that this data collection process does not impact the performance of the application.











































Let's personalize your content