
Improve Application Latency With Read Replicas Using YugabyteDB [Video]
DZone
MAY 15, 2023
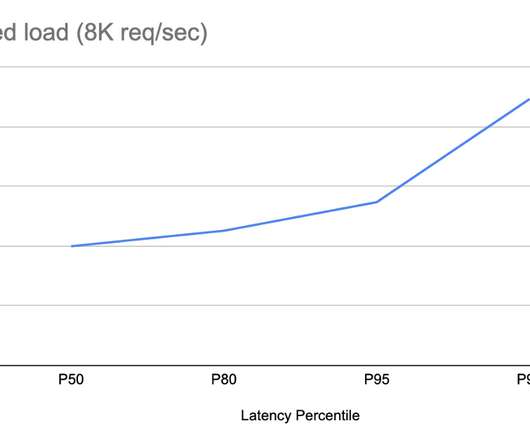
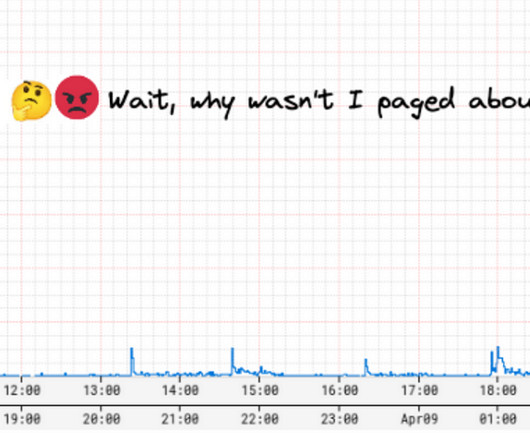
Scalability and low latency are crucial for any application that relies on real-time data. One way to achieve this is by storing data closer to the users. In this post, we'll discuss how you can use YugabyteDB and its read replica nodes to improve the read latency for users across the globe.



































Let's personalize your content