

Mastering Latency With P90, P99, and Mean Response Times
DZone
FEBRUARY 5, 2024
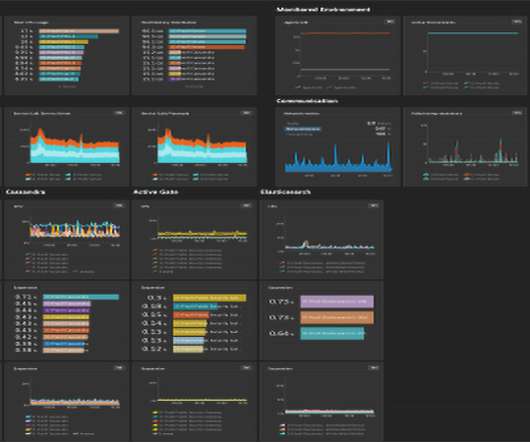
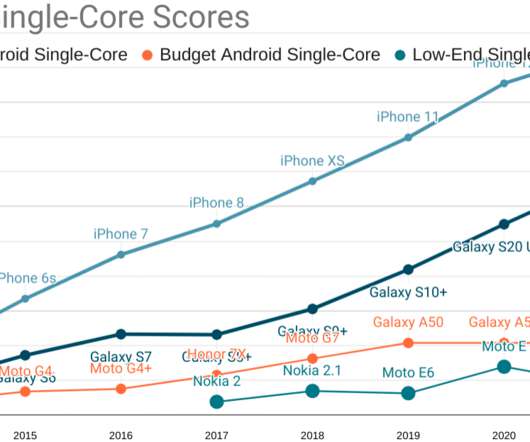
In the fast-paced digital world, where every millisecond counts, understanding the nuances of network latency becomes paramount for developers and system architects. Latency, the delay before a transfer of data begins following an instruction for its transfer, can significantly impact user experience and system performance.









































Let's personalize your content