

Migrating Critical Traffic At Scale with No Downtime?—?Part 1
The Netflix TechBlog
MAY 4, 2023
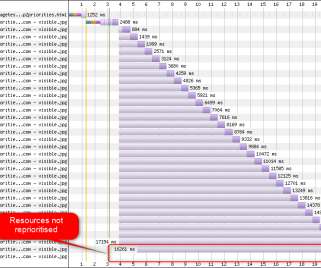
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.



























Let's personalize your content