
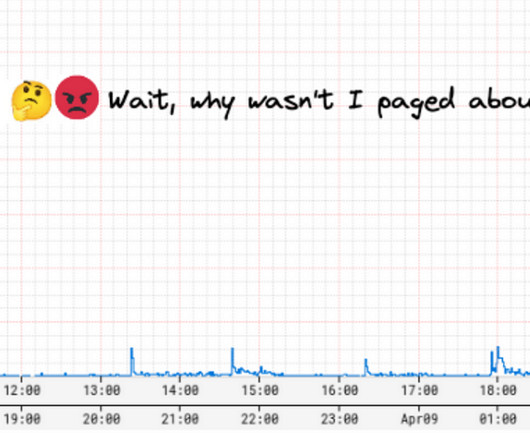
Improved Alerting with Atlas Streaming Eval
The Netflix TechBlog
APRIL 27, 2023
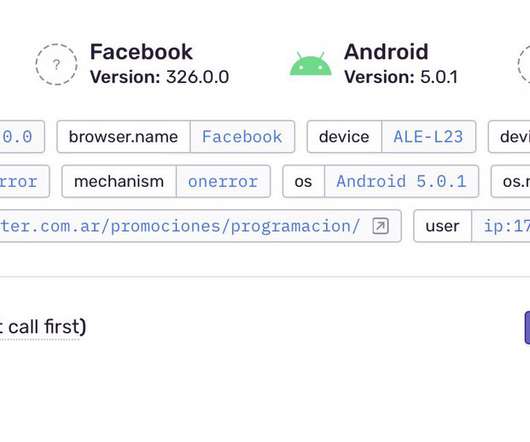
Engineers want their alerting system to be realtime, reliable, and actionable. A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! The internals here are outside the scope of this blog post.



































Let's personalize your content