

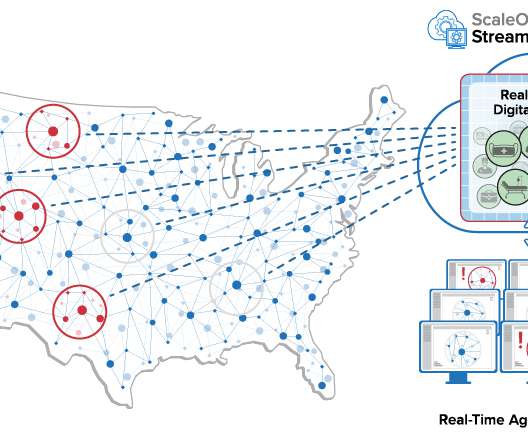
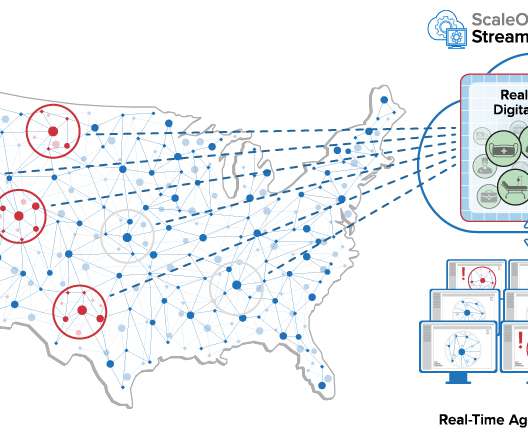
What Should You Know About Graph Database’s Scalability?
DZone
JANUARY 20, 2023
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.




































Let's personalize your content