

What is cloud monitoring? How to improve your full-stack visibility
Dynatrace
JANUARY 11, 2023
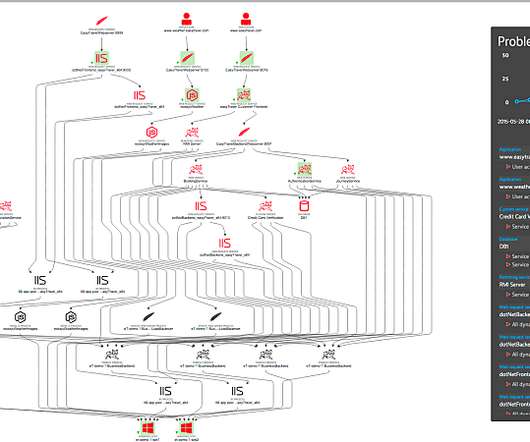
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
















Let's personalize your content