

Redis® Monitoring Strategies for 2024
Scalegrid
DECEMBER 21, 2023
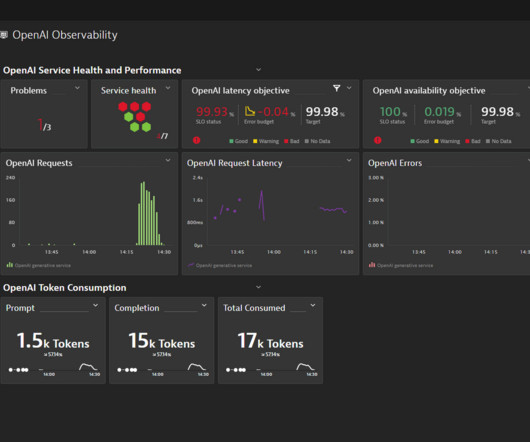
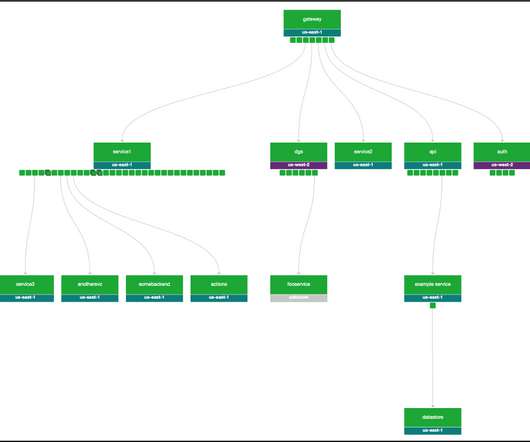
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Redis®, a powerful in-memory data store, is no exception.








































Let's personalize your content