
1. Streamlining Membership Data Engineering at Netflix with Psyberg
The Netflix TechBlog
NOVEMBER 14, 2023
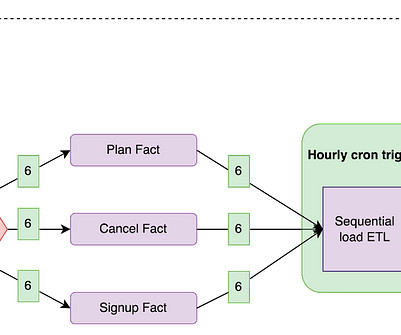
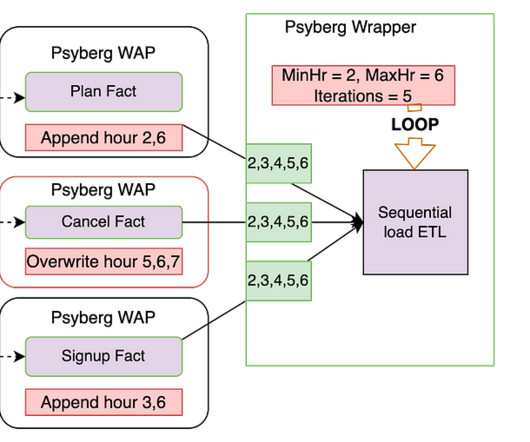
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!




















Let's personalize your content