
The Speed of Time
Brendan Gregg
SEPTEMBER 25, 2021
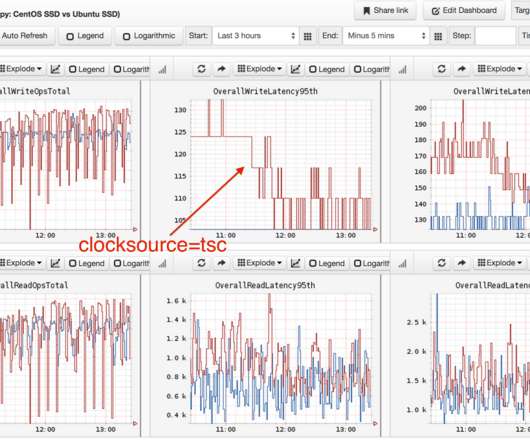
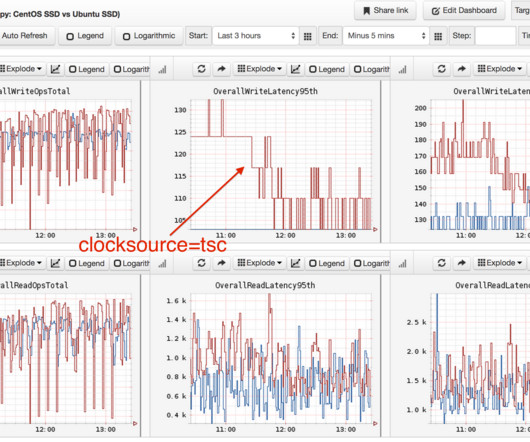
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Measuring the speed of time Is there already a microbenchmark for os::javaTimeMillis()? I've shared many posts about superpower observability tools, but often humble hacking is just as effective. Try changing the kernel clocksource.




















Let's personalize your content