

Comparing Approaches to Durability in Low Latency Messaging Queues
DZone
AUGUST 2, 2022
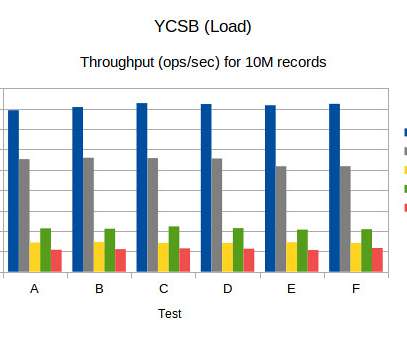
I have generally held the view that replicating data to a secondary system is faster than sync-ing to disk, assuming the round trip network delay wasn’t high due to quality networks and co-located redundant servers. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.







































Let's personalize your content