
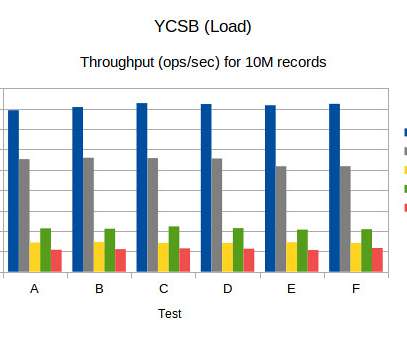
Benchmark (YCSB) numbers for Redis, MongoDB, Couchbase2, Yugabyte and BangDB
High Scalability
FEBRUARY 17, 2021
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
























Let's personalize your content