

Offline Data Pipeline Best Practices Part 1:Optimizing Airflow Job Parameters for Apache Hive
DZone
DECEMBER 27, 2023
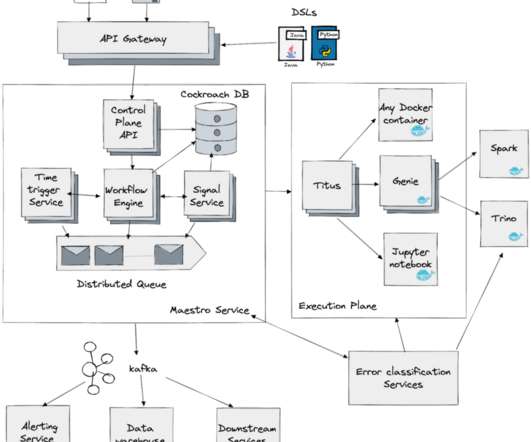
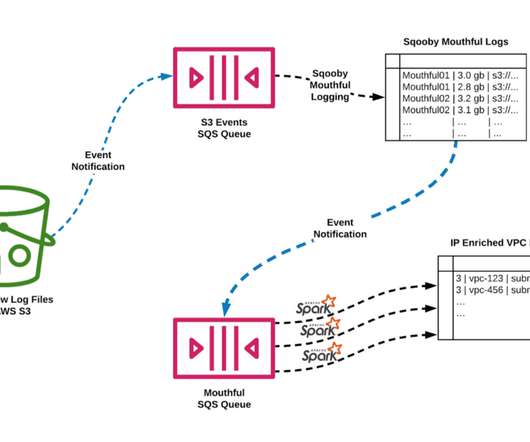
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. Working together, they form the backbone of many modern data engineering solutions.












Let's personalize your content