

Offline Data Pipeline Best Practices Part 1:Optimizing Airflow Job Parameters for Apache Hive
DZone
DECEMBER 27, 2023
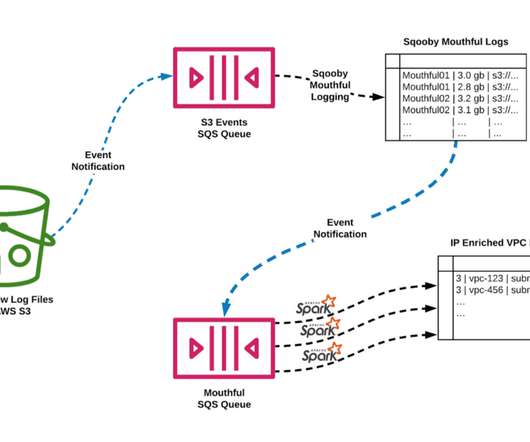
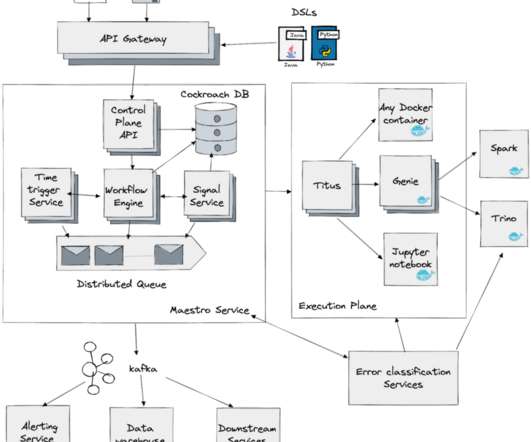
This post focuses on elevating our data engineering game, streamlining your data workflows, and significantly cutting computing costs. The need to optimize offline data pipeline optimization has become a necessity with the growing complexity and scale of modern data pipelines.












Let's personalize your content