
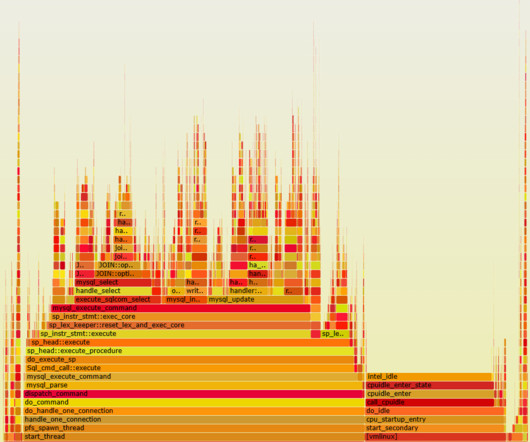
Why you should benchmark your database using stored procedures
HammerDB
OCTOBER 23, 2023
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X






















Let's personalize your content