


Enhance data management with Grail: Ultimate guide to custom buckets and security policies
Dynatrace
OCTOBER 6, 2023
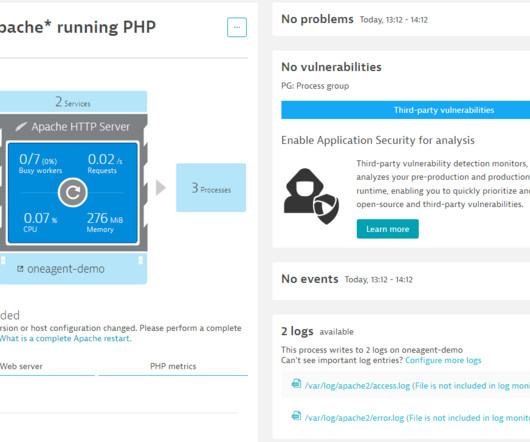
Grail: Enterprise-ready data lakehouse Grail, the Dynatrace causational data lakehouse, was explicitly designed for observability and security data, with artificial intelligence integrated into its foundation. For example, a separate bucket could be used for detailed logs from Dynatrace Synthetic nodes.


















Let's personalize your content