
Open-Sourcing Metaflow, a Human-Centric Framework for Data Science
The Netflix TechBlog
DECEMBER 3, 2019
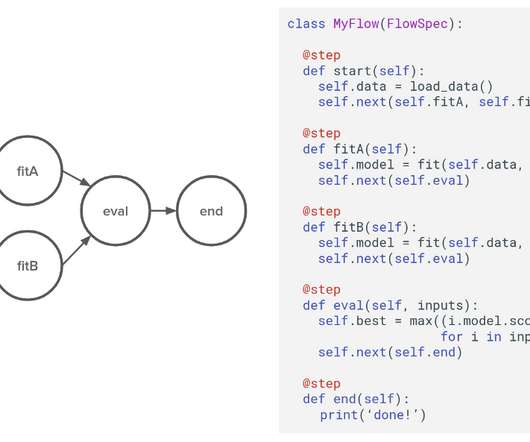
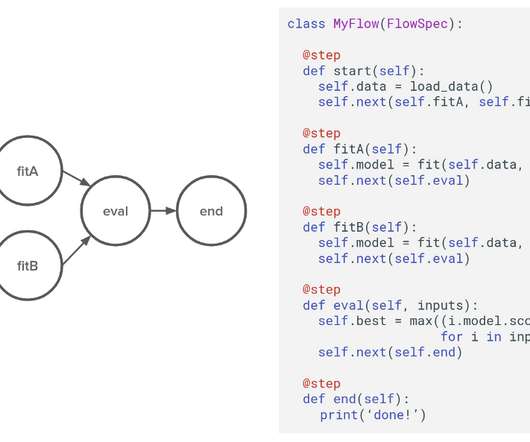
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?”















Let's personalize your content