

Building Netflix’s Distributed Tracing Infrastructure
The Netflix TechBlog
OCTOBER 19, 2020
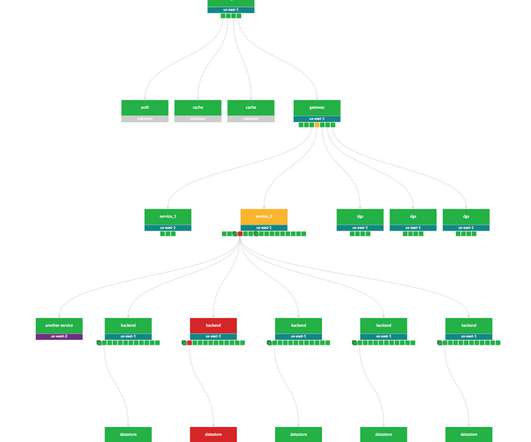
which is difficult when troubleshooting distributed systems. If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Stream Processing: to sample or not to sample trace data?










Let's personalize your content