

Mastering Scalability and Performance: A Deep Dive Into Azure Load Balancing Options
DZone
JANUARY 8, 2024
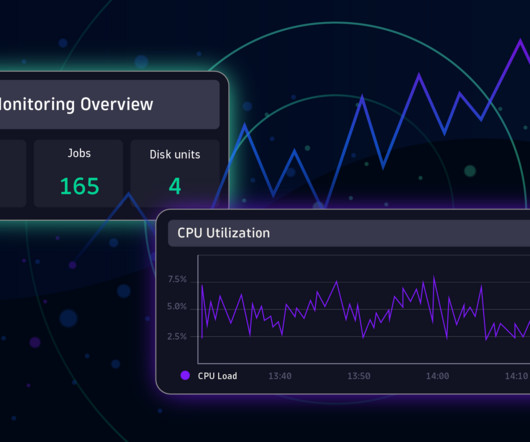
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. What Is Load Balancing? Load balancing is a critical component in cloud architectures for various reasons.














































Let's personalize your content