

What is ITOps? Why IT operations is more crucial than ever in a multicloud world
Dynatrace
DECEMBER 15, 2022
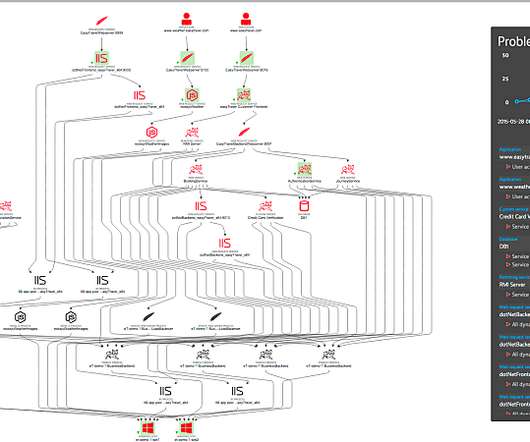
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Although modern cloud systems simplify tasks, such as deploying apps and provisioning new hardware and servers, hybrid cloud and multicloud environments are often complex.





















Let's personalize your content