

In-Stream Big Data Processing
Highly Scalable
AUGUST 20, 2013
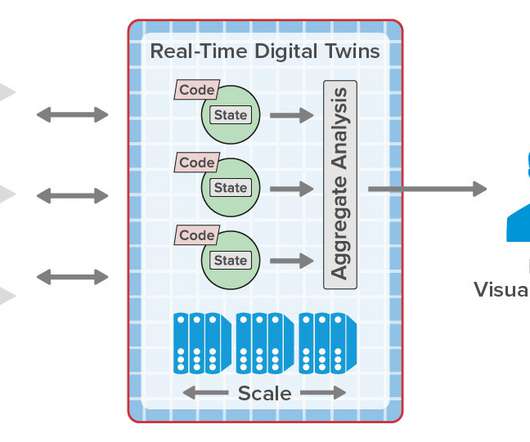
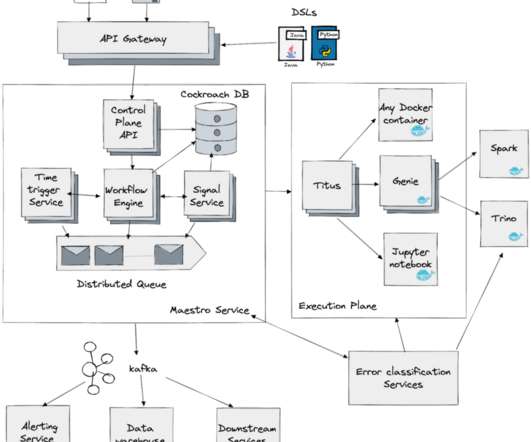
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. The engine should be compact and efficient, so one can deploy it in multiple datacenters on small clusters. High performance and mobility. Basics of Distributed Query Processing.


























Let's personalize your content