

What is a Distributed Storage System
Scalegrid
FEBRUARY 8, 2024
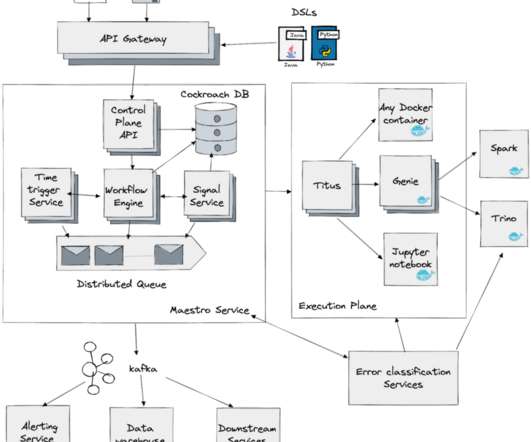
It utilizes methodologies like DStore, which takes advantage of underused hard drive space by using it for storing vast amounts of collected datasets while enabling efficient recovery processes. These systems enable vast amounts of data to be spread over multiple nodes, allowing for simultaneous access and boosting processing efficiency.


















Let's personalize your content