

Incremental Processing using Netflix Maestro and Apache Iceberg
The Netflix TechBlog
NOVEMBER 20, 2023
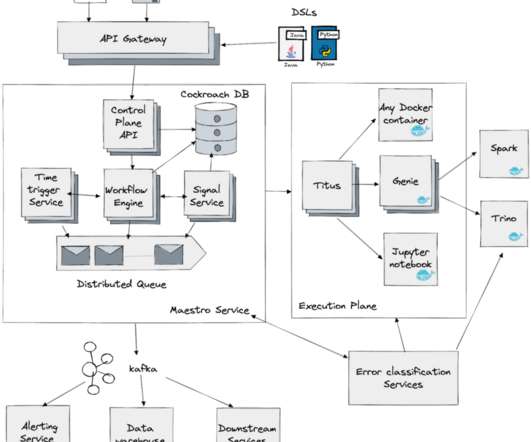
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.















Let's personalize your content