

Uber’s Big Data Platform: 100+ Petabytes with Minute Latency
Uber Engineering
OCTOBER 17, 2018
To accomplish this, Uber relies heavily on making data-driven decisions at every level, from forecasting rider demand during high traffic events to identifying and addressing bottlenecks … The post Uber’s Big Data Platform: 100+ Petabytes with Minute Latency appeared first on Uber Engineering Blog.













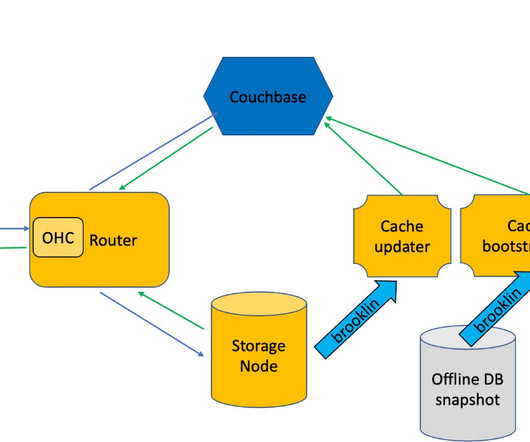

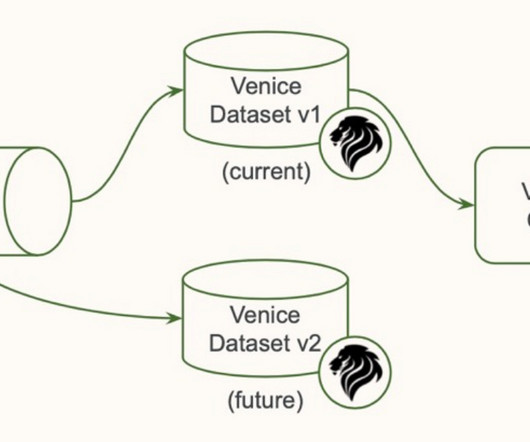








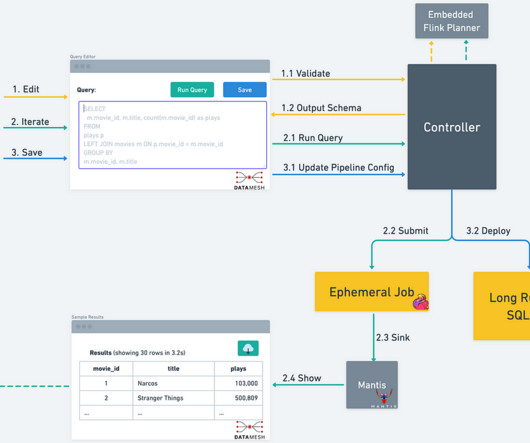






Let's personalize your content