

Netflix at AWS re:Invent 2019
The Netflix TechBlog
NOVEMBER 22, 2019
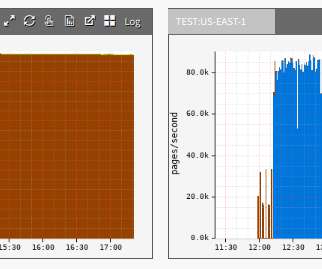
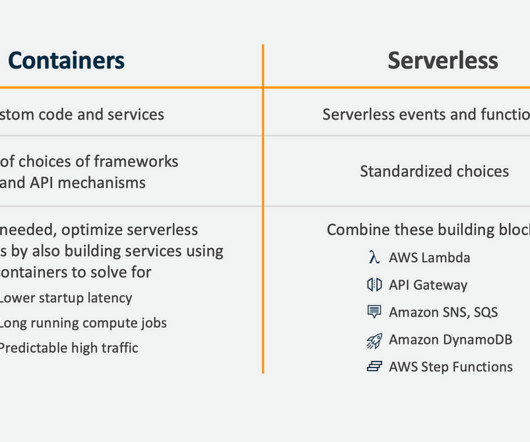
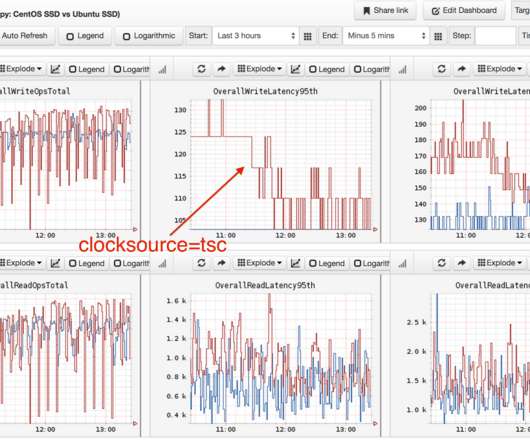
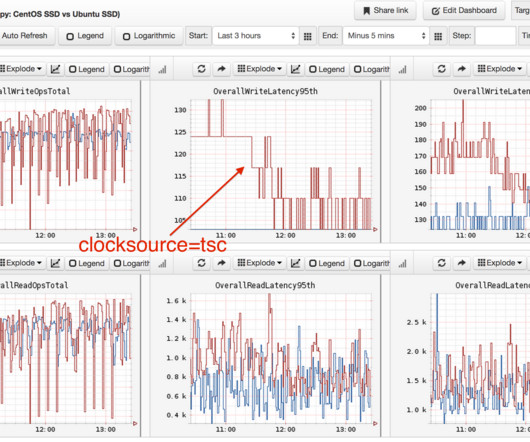
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.

























Let's personalize your content